服务热线
0530-5837666
服务热线
0530-583766618653002903
这篇文章记录看dive into pytorch遇到的所有有意义的点,主要是以后可能在吹B或者面试的时候问到的知识点,因此主要以问答的形式记录。正因为上述原因,本篇文章记录的主要是较为基础的,非严肃推导性的点。
练习代码在这里。
Q:为什么需要激活函数?
Full Connection Layer只是对数据的仿射变换,而多个仿射变换的叠加本质上仍然是一个仿射变换,解决的方法就是引入非线性变换,如对隐藏变量使用按元素运算的非线性函数,作为下一个全连接层的输入。Q:什么是训练误差?什么是泛化误差?二者关系是什么?
前者指模型在训练集上表现出来的误差,后者指模型在任意一个测试数据样本上表现出来的误差的期望。基于独立同分布假设,任意一个给定的ML模型,他的训练误差和泛化误差都是相同的。但是实际上,模型的参数是在训练集上训练的,依据的是最小化训练误差,所以训练误差的期望小于或等于泛化误差。因为无法从训练误差估计出泛化误差,所以一味地降低训练误差不等于泛化误差也会降低。Q:导致过拟合的原因?
1.模型过于复杂。2.训练集不够大。Q:权重衰减(L2正则化)是怎么防止模型过拟合的?
Q:model.eval()的作用?
主要在于关闭Dropout。Dropout的定义为小于某个概率阈值P0的cell清零,大于P0的cell会被除以1-P0做拉伸,这保证了不改变其输⼊的期望值。在测试模型的时候,人们期望得到确定性的结果(特定输入就得到特定输出),所以要关闭Dropout,这也就是eval模式的作用(之一)。Q:在深度学习中,卷积和互相关运算的关系?
互相关运算是指以滑动窗口的形式将输入矩阵和核矩阵对应计算乘积和,得出结果矩阵;卷积运算是指将核矩阵左右翻转再上下翻转后得到的新矩阵进行互相关运算。因为卷积核的参数信息都是不断更新学习得来的,所以本质上在深度学习中,卷积就是一种互相关运算(最后会收敛到等效的参数上)。Q:什么是特征图?什么是感受野?
二维卷积层输出的二维数组可以看做是输入在空间维度(宽和高)上某一级的表达,叫做特征图。影响元素x的前向计算的所有可能输入区域(可能大于输入实际尺寸)叫做x的感受野。Q:1*1卷积的作用?
因为1*1是卷积的最小窗口,失去了卷积层可以识别高和宽维度上相邻元素构成模式的功能。实际上1*1卷积的主要计算发生在通道维度上,通过使用不同数量的kernel,可以得出不同通道数量的输出。假如将通道当做特征维,宽高的元素当做数据样本,那么1*1卷积的作用与全连接层类似。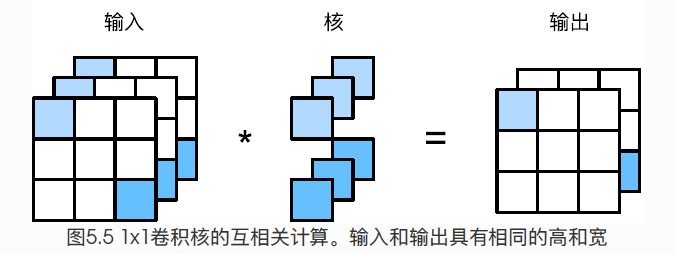
Q:池化层(pooling)的作用?
缓解卷积层对位置的过度敏感性。使用p*q池化时,只要卷积层的识别模式在高和宽上移动不超过p-1(q-1)个像素,都可以被检测出来。Q:LeNet、AlexNet和VGG?
这三个是典型的卷积网络。卷积层主要解决两个问题:1.卷积层保留输入形状,使图像在高和宽两个方向上的相关性均可能被有效识别;2.卷积层使用滑动窗口将同一个卷积核与不同位置的输入重复计算,避免了参数尺寸过大。LeNet是最早的卷积网络,用于10分类,sigmoid为激活函数,具体结构如下: FashionMINST,GF940MX 2G显卡 20 sec/epochAlexNet则是第一个深度卷积网络,他包含5层卷积、2层隐藏层和1层全连接输出层。因为后面3层全连接参数过大(接近1GB),Alex设计了双数据流,使得数据在两块GPU上并行处理(不同硬件上的数据是没办法交互计算的),这在现在当然不是问题了。AlexNet用了更简单的ReLU,求导更简单而且不会出现梯度消失的问题,sigmoid在x值特别大时,对应的导师f`(x)趋向于0,不利于BP。AlexNet使用了Dropout,提升了泛化性的同时,减少了计算量。AlexNet使用了图像增强,如翻转裁切和颜色变化,扩大了数据集以缓解数据过拟合。具体结构如下:
FashionMINST,GF940MX 2G显卡 20 sec/epochAlexNet则是第一个深度卷积网络,他包含5层卷积、2层隐藏层和1层全连接输出层。因为后面3层全连接参数过大(接近1GB),Alex设计了双数据流,使得数据在两块GPU上并行处理(不同硬件上的数据是没办法交互计算的),这在现在当然不是问题了。AlexNet用了更简单的ReLU,求导更简单而且不会出现梯度消失的问题,sigmoid在x值特别大时,对应的导师f`(x)趋向于0,不利于BP。AlexNet使用了Dropout,提升了泛化性的同时,减少了计算量。AlexNet使用了图像增强,如翻转裁切和颜色变化,扩大了数据集以缓解数据过拟合。具体结构如下: GF940MX 2G显卡 700 sec/epochAlexNet虽然在网络结构上只是LeNet的简单增加,但是科研思路和精度提升却是有非常重大意义的。AlexNet和LeNet虽然是卷积网络,但是没有给后来者提供进一步的研究思路。VGG提出了可以复用简单模块来构建深度模型的思路。VGG提出的简单模块称为VGGblock,连续使用数个相同的填充为1,窗口形状为3*3的卷积核,最后接上一个步幅为2,窗口形状2*2的最大池化。结果就是数据每过一个VGG_block,尺寸就减半。VGG-11的结构如下:
GF940MX 2G显卡 700 sec/epochAlexNet虽然在网络结构上只是LeNet的简单增加,但是科研思路和精度提升却是有非常重大意义的。AlexNet和LeNet虽然是卷积网络,但是没有给后来者提供进一步的研究思路。VGG提出了可以复用简单模块来构建深度模型的思路。VGG提出的简单模块称为VGGblock,连续使用数个相同的填充为1,窗口形状为3*3的卷积核,最后接上一个步幅为2,窗口形状2*2的最大池化。结果就是数据每过一个VGG_block,尺寸就减半。VGG-11的结构如下: 这就不难为我的小卡了吧一个224*224的图像经过VGG-11的5个block后,尺寸变化为7*7。
这就不难为我的小卡了吧一个224*224的图像经过VGG-11的5个block后,尺寸变化为7*7。
Q:什么是Network in Network(NiN)?
在AlexNet中因为末尾的三个全连接层的参数太大,Alex做过一些改进。NiN也是改进之一,它兼具VGG的block思想和减少AlexNet参数的思想,核心做法是用1*1卷积代替全连接层,使用1*1卷积将卷积层通道数变为类别数,然后使用全局平均池化(即kernel等于特征size)得出对应输出。NiN的好处是可以显著减小模型参数尺寸,缓解了过拟合问题。但是实际过程中,NiN的收敛时间要长于VGG等全连接输出层。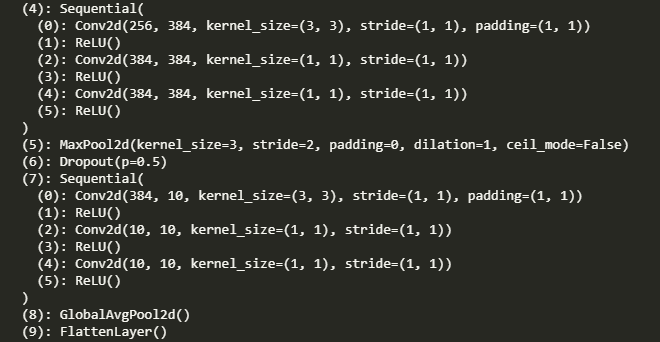 哈哈哈 VSC修好了
哈哈哈 VSC修好了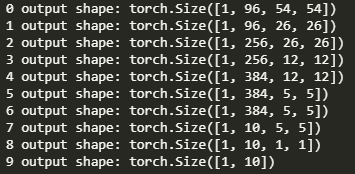 1*224*224的图片尺寸变化 629 sec/epoch,训练的快,收敛的慢
1*224*224的图片尺寸变化 629 sec/epoch,训练的快,收敛的慢Q:什么是GoogLeNet?
GoogLeNet和VGG-11是2014年imageNet挑战赛的第一、二名,两者拥有相似的思想,那就是分块。相比于VGG-11,GoogLeNet在通道设计和深度上都更复杂,核心在于并行结构的Inception块。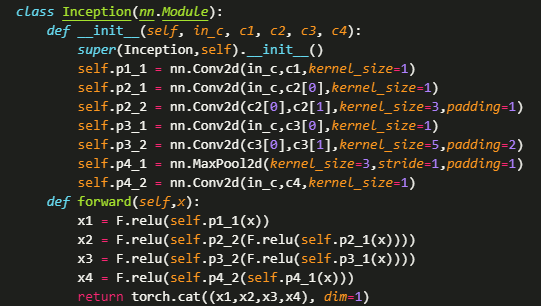 四路并行
四路并行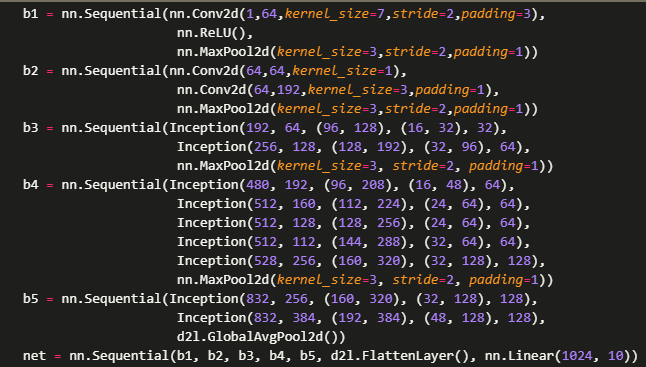 GoogLeNet第一版本架构 大卷积核明显少虽然模型看着更复杂,但是实际上计算复杂度是更低的,可以说是一个更加精妙的设计。至于Inception块的通道设计分配比例,则是在ImageNet数据集上大量数据实验得来的。
GoogLeNet第一版本架构 大卷积核明显少虽然模型看着更复杂,但是实际上计算复杂度是更低的,可以说是一个更加精妙的设计。至于Inception块的通道设计分配比例,则是在ImageNet数据集上大量数据实验得来的。Q:简单理解Batch Normalization?
训练时使用BN,不断调整网络中间层的输出,从而使网络更稳定。BN分为对Conv的和对FC的,两者稍有不同。和Dropout一样,训练模式和测试模式下输出是不同的。因为训练时用的是一个batch的均值和方差,而测试时用的是移动平均估算整个数据集的均值和方差。Q: 什么是ResNet和DenseNet?
对于NN,原则上对充分训练的模型添加新的层,训练误差都会降低,因为原模型的解空间是新模型解空间的子集。特殊的,如果后添加的层如果能拟合成恒等映射f(x)=x那么新模型和原模型同样有效。 然而,实际上过深的层使得误差不降反升。即使BN使得数值稳定性提高,训练深层模型更容易,但是误差上升的问题依旧没有解决。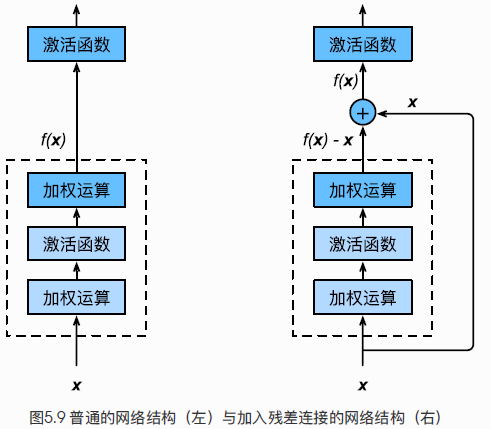 假设虚线框内为一局部拟合函数,目标是f(x)。那么普通网络结构的目标是拟合f(x),ResNet则拟合f(x)-x。基于上述的恒等映射思想,拟合f(x)-x=0比f(x)=x更容易优化。实际上,权重W和偏差b都接近于0,更容易捕捉恒等映射的细微波动。(也不太懂,你说是那就是)具体实现则是依靠残差块,以ResNet-18 结构为例:每个 Residual 结构 2 个 conv(Not 1*1)每个 残差块(blk) 2 个 Residual 结构共计 4 个 blk 16 个 conv输入层的 conv + 输出的 FC共计 18 层
假设虚线框内为一局部拟合函数,目标是f(x)。那么普通网络结构的目标是拟合f(x),ResNet则拟合f(x)-x。基于上述的恒等映射思想,拟合f(x)-x=0比f(x)=x更容易优化。实际上,权重W和偏差b都接近于0,更容易捕捉恒等映射的细微波动。(也不太懂,你说是那就是)具体实现则是依靠残差块,以ResNet-18 结构为例:每个 Residual 结构 2 个 conv(Not 1*1)每个 残差块(blk) 2 个 Residual 结构共计 4 个 blk 16 个 conv输入层的 conv + 输出的 FC共计 18 层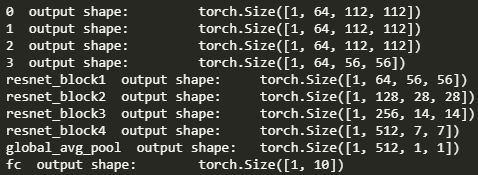 224*224的图片尺寸和通道变化DenseNet则是将元素相加操作换成了通道连接操作,一个dense块内的conv会用到前面所有的输入通道。其中尺寸是相同的,但是通道数会逐渐加大。所以需要一个1*1卷积层调整通道数,使之不会太夸张,成为过渡层。
224*224的图片尺寸和通道变化DenseNet则是将元素相加操作换成了通道连接操作,一个dense块内的conv会用到前面所有的输入通道。其中尺寸是相同的,但是通道数会逐渐加大。所以需要一个1*1卷积层调整通道数,使之不会太夸张,成为过渡层。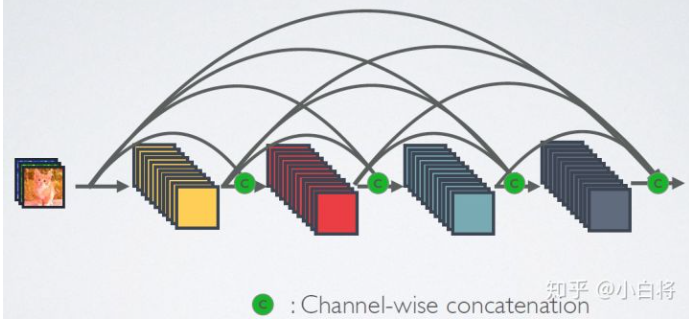
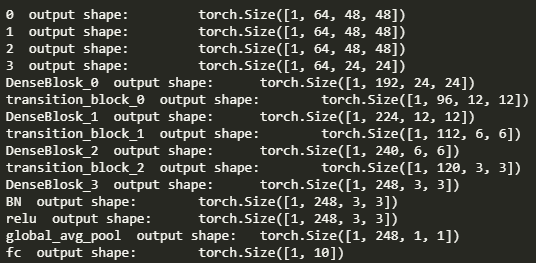 96*96的图片尺寸和通道变化ResNet使用stride=2的残差块使feature map的size减半,DenseNet则在过渡层1*1conv之后在接一个kernel=2的池化,使得feature map的size减半。
96*96的图片尺寸和通道变化ResNet使用stride=2的残差块使feature map的size减半,DenseNet则在过渡层1*1conv之后在接一个kernel=2的池化,使得feature map的size减半。To Be Continued
地址:高新区万福办事处吴拐行政村 电话:0530-5837666 邮箱:2586826320@qq.com

关注我们